I’ve been tasked with the following assignment: Please make a nodejs program that downloads a web page (any web page will do) and give a list of links on the page (any tags)
Breaking down the requirements, I need a way to get the URL from the user, a way to find the URL provided, a way to save the website to the user’s system, and finally a way to display the links to the user. From a usability standpoint, it feels like it might be helpful to let the user select one of the links to run the program again without restarting it.
Installing Packages
First, I’m going to need some packages to help make this program:
- axios – to get the website url
- cheerio – to parse the website HTML
- fs – to write a file to the system
- readLine – to create a UI in the terminal
I used npm to install my packages and set up readLine to create my input/output interface.

Finding and Returning Links
The first function I’m going to build will be the logic for extracting the links from the given HTML. It takes a string of HTML as the parameter, then loads it into a cheerio object where I can parse the string for elements to extract.
Next, I’ll use that object to search for all instances of anchor tags. For example, here’s what a standard HTML link looks like:
<a href="link-address.html">Text To Click</a>The function will look for all instances of the ‘a’ tag, then extract the ‘href’ value from what is found. If a value is found, the link will be pushed to the array of links.

Getting Website Information From a URL Input
Now I need to actually get the HTML to pull the links out of. Since I’m going to make a call to an external url, I’m going to create an async function that will wait for the URL data to be returned, and save that in a ‘html‘ variable.
Next, I’m going to get the links from the returned HTML by calling the getLinks() function, and prepare to create the .html file. I’m going to extract the page title, if it’s available and add that to the file name, to help sort through records if the user is going to download different web pages. The file will be saved as ‘download_[web page title].html’

After the fileName is generated, I can write the file to the system using the ‘fs‘ package. The file name, and the html string are passed as parameters. If it’s successful, the console logs will inform the user that the website was downloaded (to the same directory main.js is running from), and the list of links will be displayed.

The last thing I’m going to want to do here is to use readLine to make some prompts for the user, and to add the logic to react to the inputs. If the user just wanted to download the one file, they can enter ‘0’ to exit the program. If the user also wants to download other links found on the page, they can enter the associated link number to run the program again. Please note that some links found will not be returned as a full address, and will get a 404 error from axios.
Running and Testing
Now I’m going to give it a try. First I need to open the terminal and navigate to where I have the program saved. Next I’ll use the command ‘node main.js’ to run the main.js file. Once that’s running the user will see a prompt to accept a URL. I’m going to use my local library’s website as it’s a pretty standard HTML website.

Once the user hits enter, the website will be downloaded and the links are displayed. Most of these links are the full address, so we can successfully download most of these links.

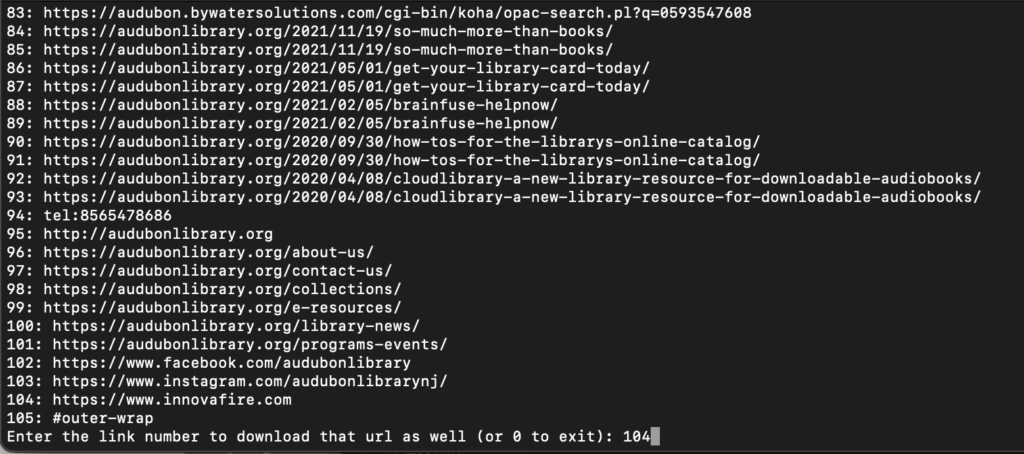
At the bottom of the list of links the user is prompted to run the program again, or to enter 0 to exit. I see link #104 is can external link, so I’m going to give that a try by entering the number into the prompt and hitting enter.
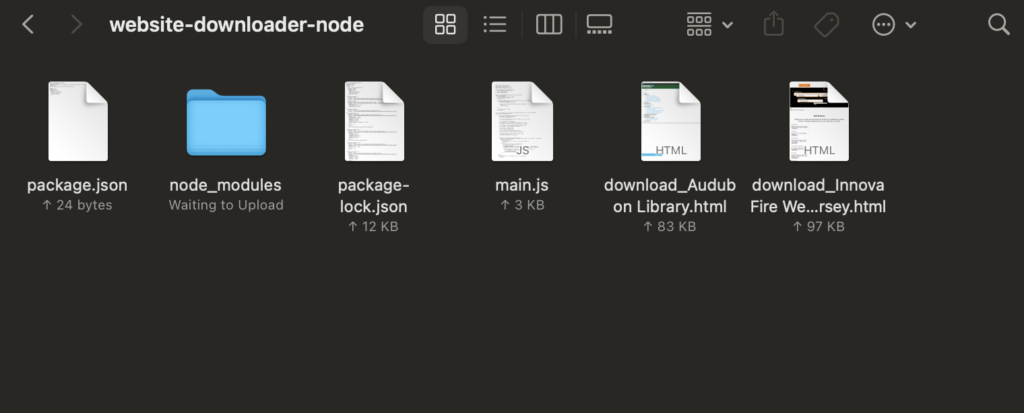
Now I’m just going to navigate to the folder in my file system and see that I now have two HTML files – The Library’s home page, and the external address for Innova Fire.
Now I’m going to test my edge cases to ensure that no invalid entries are being processed by the system, and I’ve run into something that I can improve. When an invalid entry is detected, the user is alerted, but they don’t have a good path to fixing the mistake.

To fix this, I’m going to go back to the downloadWebsite() function and add a while loop to listen for user input instead of waiting on a basic input/output flow.
Improving and Testing
A while loop is going to be the cleanest way to implement this kind of ‘try again’ logic so that’s what I’m going with. This loop will essentially run forever until the user closes the terminal or choses to exit the program using the number 0.
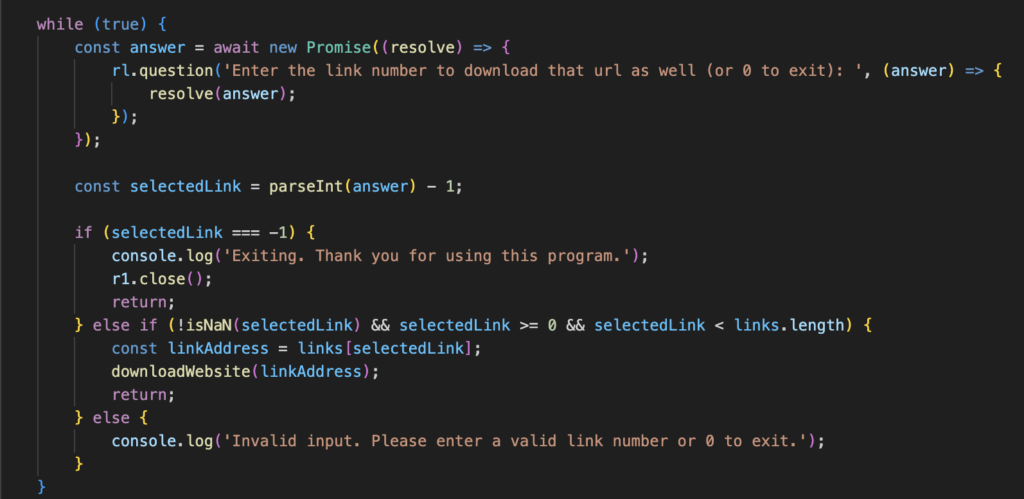
As you can see, it looks a lot like it did before, but the validation is reversed. I’m parsing the number that the user input – if they enter 0 it will result in an answer of -1 due to compensating for index numbers, so if answer is -1 the program will close. I’ll then perform the validation on the answer, ensuring that it is a number AND it’s greater than 0, AND the number is smaller than the length of the links array.
If the validation checks are all true, then we’ll get the link address out of the array and run the function again. Otherwise it was an invalid input and the program will ask again.

When I run the program again, using the same website for the Audubon Library, you can see I can try multiple invalid entries, eventually downloading Innova Fire’s website again.
What’s Next
I believe I’ve satisfied the requirements and the user’s experience flows pretty smoothly, so I think I’m done here. There is room for improvement though. Possible next steps could involve removing links that start with a ‘/‘ from the returned list. I could consider adding express to the node file to create an API for a front-end web user interface. I could create a simple interface with HTML and Javascript, or a single page React app to improve usability and experience. But that’s all for now!
Leave a Reply